
Rethinking Bank Reconciliation: A Smarter Approach to Matching Transactions at Scale
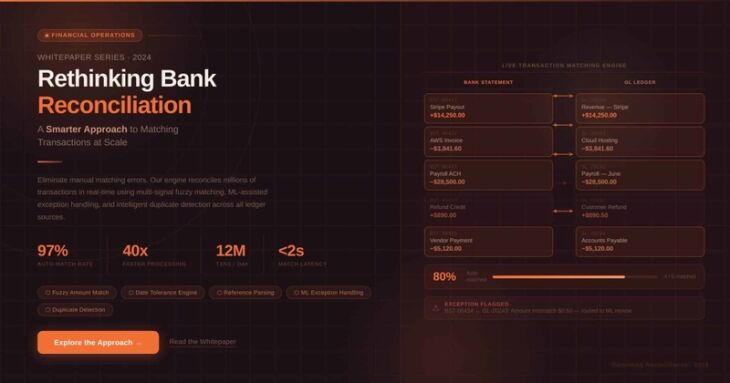
Bank reconciliation is one of those processes that sounds straightforward until transaction volumes increase, exceptions start piling up, and every client introduces their own way of doing things.
On paper, reconciliation is simple: compare bank statements against the general ledger and identify what matches. In reality, businesses quickly run into challenges that traditional rule-based approaches struggle to handle.
Descriptions vary, payroll transactions are grouped differently, a single bank transaction may correspond to multiple entries in the ledger…even two clients in the same industry can have entirely different reconciliation requirements.
To address these complexities, the Bista team has designed a reconciliation architecture that combines deterministic matching methods with intelligent decision-making. The goal isn’t to replace existing processes but to create a structured flow that can adapt to different scenarios while maintaining accuracy.
The architecture can operate in two ways: one for organizations with historical reconciliation data available, and another for situations where no prior history exists.
Starting With Historical Data Creates a More Context-Aware Reconciliation Process
When historical reconciled data is available, the process begins by loading previously matched Bank Statement and General Ledger records.
These historical matches provide context. Instead of treating every reconciliation cycle as a brand-new exercise, the system can recognize patterns that already exist within a client’s transaction history.
This historical context helps reduce ambiguity and creates a foundation for more accurate matching throughout the process.
Client-Specific Rules Are Established Early in the Process
Once historical data is available, an LLM is used to generate or retrieve client-specific reconciliation rules.
These rules can include:
- Transaction description patterns
- Tolerance thresholds
- Account-specific groupings
Every organization has its own nuances, and hardcoding those variations is difficult to maintain over time. By dynamically interpreting these rules, the reconciliation process can adapt to different client environments without requiring extensive manual configuration.
These rules continue to influence the reconciliation flow from this point onward.
The System Determines Whether Checkbook Matching Is Necessary
Not every reconciliation process requires checkbook matching, so the architecture introduces an early decision point.
If checkbook matching is required, the system follows a sequential process:
- Check Number Match: performs precise check-level lookups.
- Python Direct Match: performs exact transaction-level matching.
- Python Batch Match: handles scenarios where one bank statement transaction corresponds to multiple General Ledger transactions.
If checkbook matching is not required, the system skips the check-level lookup and moves directly into Python Direct Match, followed by Python Batch Match.
This prevents unnecessary processing while ensuring more complex scenarios are still handled appropriately.
The Main Reconciliation Engine Handles the Transactions That Rules Alone Cannot Resolve
After the deterministic matching stages are complete, both paths converge into the main reconciliation stage.
At this point, the system applies both client-specific rules and default reconciliation rules to perform intelligent transaction matching.
This layer is designed to address situations that traditional matching techniques often struggle with, including:
- Partial description matches
- Rounding differences
- Multi-line transaction splits
Rather than relying exclusively on exact matches, the reconciliation process can evaluate context and make more informed decisions.
Payroll Requires Its Own Reconciliation Logic
Payroll transactions introduce another layer of complexity.
For this reason, payroll reconciliation is handled separately.
If payroll data is available, the architecture routes the transactions through a dedicated payroll reconciliation process designed specifically for batch disbursements.
These scenarios often involve matching a single General Ledger entry against multiple bank statement transactions, requiring a different approach than standard reconciliation.
If payroll data is not present, the process bypasses this step entirely.
Every Path Leads to a Single Reconciliation Output
Regardless of which path the transactions take, everything converges into a final output.
The reconciliation report includes:
- Matched transaction pairs
- Unreconciled items
The objective is not simply to identify successful matches, but also to clearly surface exceptions that require additional review.
How the Process Changes When Historical Data Doesn’t Exist
There are situations where historical reconciliation data simply isn’t available.
This can happen when:
- Onboarding a new client
- Performing a first-time reconciliation
- Recovering from a data loss event
In these scenarios, the process begins with only two inputs: the Bank Statement and the General Ledger.
Without historical context, the system cannot derive client-specific rules. Instead, it relies entirely on default reconciliation logic.
The reconciliation flow remains largely the same. The system still determines whether checkbook matching is required and still executes its matching stages.
The biggest difference is that the main reconciliation process uses generalized reconciliation heuristics rather than rules tailored to a specific client’s historical behavior.
While less customized, this approach still allows the system to handle a broad range of transaction types and establish a reliable starting point.
A Flexible Architecture Designed for Different Reconciliation Scenarios
No two organizations reconcile transactions the same way.
Some have years of historical data available. Others may be starting from scratch. Some require checkbook matching, while others need specialized payroll handling.
Instead of forcing every reconciliation process into a single rigid workflow, this architecture adapts to the information available and applies the appropriate matching strategy at each stage.
By combining deterministic matching techniques with intelligent reconciliation logic, the process can support both highly customized environments and first-time implementations.
About This Solution
This bank reconciliation architecture was developed by Bista Solutions as a custom solution within Odoo ERP to support more intelligent, scalable reconciliation processes.
The architecture is designed to accommodate different reconciliation scenarios, whether an organization has years of historical data available or is performing reconciliation for the first time. By combining structured matching techniques with intelligent decision-making, the solution helps create a more adaptable and context-aware reconciliation process without introducing unnecessary complexity.
Watch an Automated Bank Reconciliation Demo: